How To Load Data Into A Scratch Org
Loading data into a Salesforce scratch org can be beneficial for various reasons. Firstly, it can enable developers to test their code with realistic data and configurations, identifying and fixing issues before deploying to production.

Table of contents
Hutte Expert Panel
Here are the experts we collaborated with to bring you unique insights.
Article Highlights
- The article discusses how loading data into scratch orgs is beneficial for testing and development, but also highlights the challenges such as time consumption, data privacy concerns, and limited storage capacity.
- It introduces Hutte as a third-party tool that simplifies the process of loading data into scratch orgs, offering features like a visual web-based user interface, integrated Git hosting tools, and a pool of pre-created orgs for quick environment setup.
- Emphasizes the importance of collaboration in managing scratch orgs, stating that Hutte facilitates code sharing, data loading, dependency management, and workflow optimization, leading to increased productivity and efficiency.
It can also replicate data from production in a non-production environment, facilitating testing and development without affecting the production environment. This can be especially useful for debugging issues or testing new features.
🙅🏻♂️
Additionally, loading data into a scratch org can help ensure data consistency across different environments, allowing developers to work on the same dataset and avoid conflicts or inconsistencies.
But there are limitations to loading data into a scratch org, which include the following:
Loading data into a scratch org can be time-consuming
This can slow down the development process and impact developer productivity.
Loading sensitive or confidential Salesforce data into a scratch org can raise data privacy concerns
Developers must ensure that they are not violating data privacy laws or regulations and that the data is protected appropriately.
Scratch orgs have limited storage capacity in Salesforce
Loading large amounts of data can quickly exhaust the storage limits. Developers may need to consider data size and storage capacity when loading data into scratch orgs.
Loading data into a scratch org can also create inconsistencies between different Salesforce environments
This is especially true if the data in the scratch org is not kept up-to-date with the data in production or other environments. This can lead to confusion and errors in development and testing.
Loading data can require data manipulation and cleaning
Developers may need to spend significant time ensuring their data is correctly formatted and structured in Salesforce before loading it into a scratch org.
To address these cons, companies often use third-party tools, like Hutte, to simplify and enhance the capabilities of loading data into their scratch orgs.
Hutte enhances the functionality of your scratch orgs
When using Hutte's YAML push script, you can define what happens when scratch orgs and development environments are spun up.
You can also execute any arbitrary amount of code. Additionally, you can push data or metadata using native SFDX within your script.
🧑🍳
One of the many benefits of using Hutte is that you don't need to install or learn Git, as our UI already has integrated recipes on Git hosting tools.
Furthermore, you can pull and export your data.
Everything is generated and integrated with Hutte, so there's no need to reproduce any data.
To try out Hutte, start a free 30-day trial or check out our demo.
In this article, we'll explain how to load data into a scratch org and manage it with Hutte.
Enjoy a collaboration-friendly environment for your scratch org creation
👍
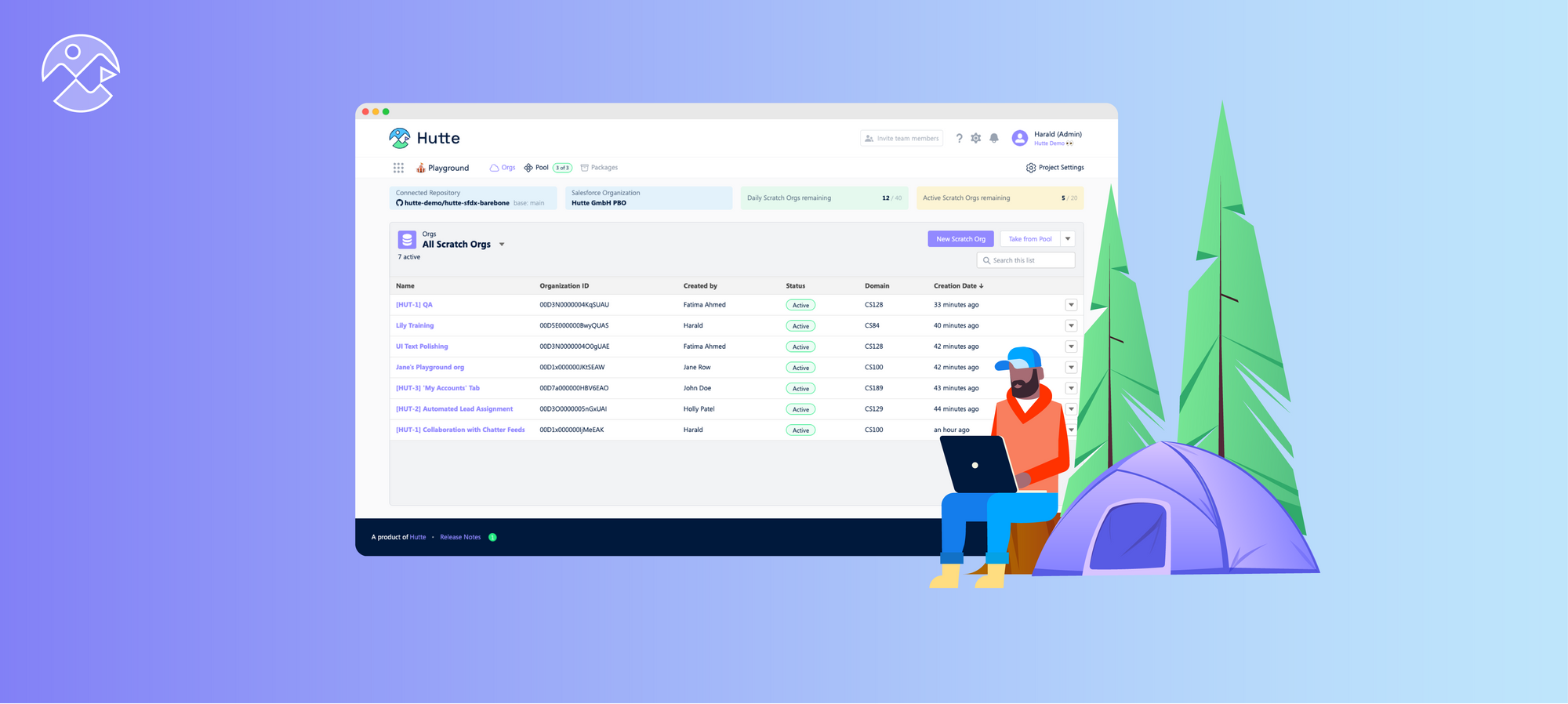
Using the "New scratch org" button, multiple users can create their own scratch orgs, which the team can access collectively.
With Hutte, you can select a Git branch from which you want to create your environment and name it. All your scratch orgs will be stored in one place, allowing you to view a historical overview or project snapshots, apps, and codebases created in Git.
This feature is especially helpful for teams that want to collaborate and contribute to each other's work.
Without Hutte, relying solely on CLI can be challenging. However, with Hutte, you can easily:
- Load data
- Make changes to the latest state of your source
- Implement new features
- Ship them to Git.
🌳
Once integrated with Hutte, developers can load the data on the scratch orgs page rather than manually telling the team that they have provisioned an environment. The team can find the branch by clicking "New scratch orgs," creating a scratch org from that branch, and viewing it in their list of scratch orgs.
You won't need to run the code locally or worry about blocking your machine, as it will run asynchronously on Hutte's infrastructure. When your scratch org is ready, you can log in and test it without affecting other users' data.
Essentially, Hutte empowers users to manage and select their own environments easily, simplifying the scratch org data loading process.
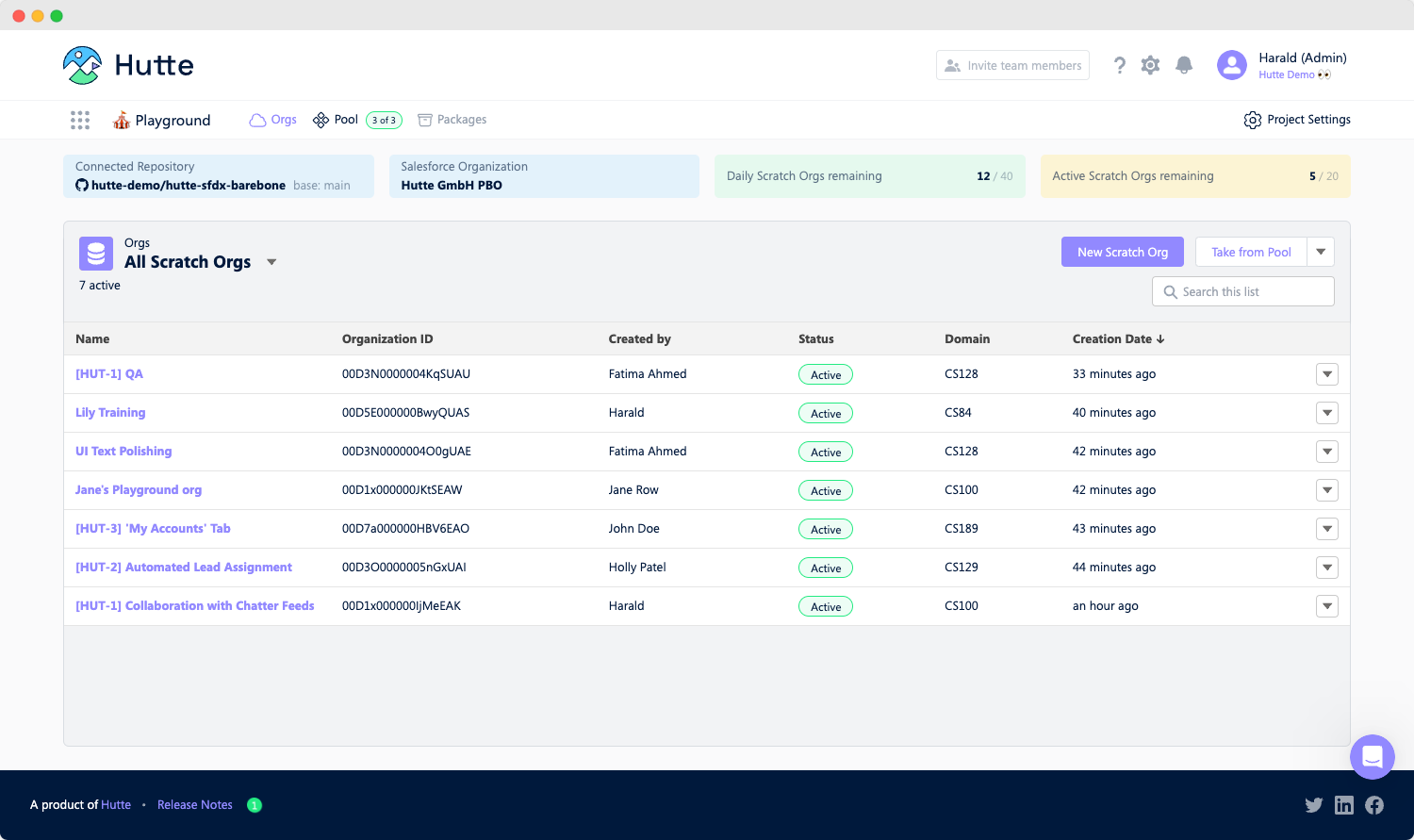
Take from the pool
🏊♂️
Hutte provides a pool of pre-created orgs, allowing you to quickly and easily spin them up without any wait time. By selecting a scratch org from the pool, you can further speed up the process when you need an environment from the latest state of your source.
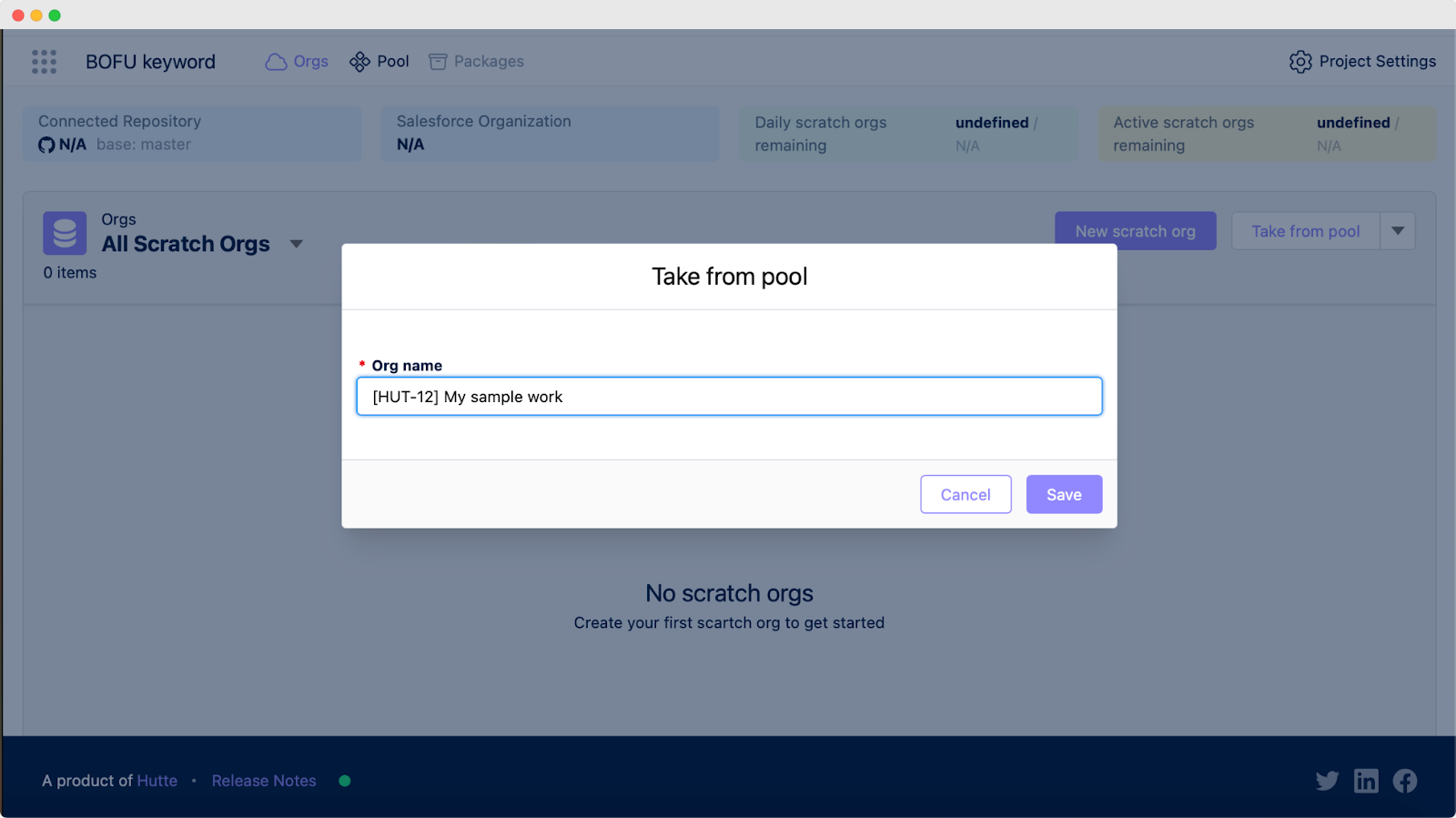
To claim a pool, select "Take from the pool" and enter the desired pool name. To customize your pool, go to "Settings" and adjust its size and duration.
This feature allows you to adjust the size of your pool according to your needs, providing flexibility and control over your resources and data.
Hutte’s Jira plugin
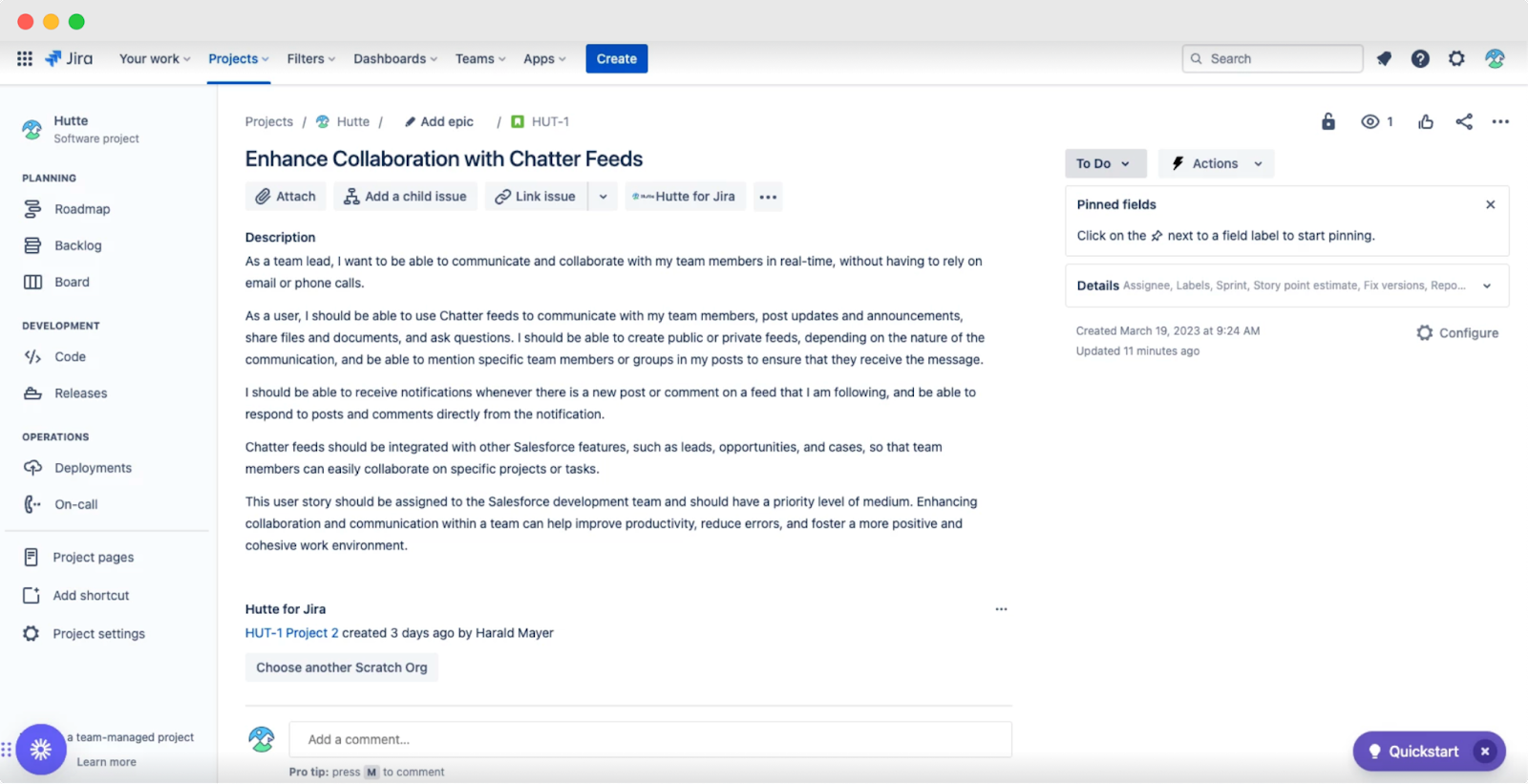
If you use Jira, you will find a corresponding work item. Hutte's Jira plugin can then identify scratch orgs referencing the same name as your work item (or issue).
💬
As a product manager, you can leave a comment for the developer who worked on the scratch org you selected. This feature facilitates collaboration without interfering with or overriding the work done by a developer.

Hutte is truly one of the best tools that we use. Product owners, Salesforce solution architects, business analysts — anyone on our team can easily and visually accomplish the tasks that would otherwise take a lot of clicks, time, and coding.
Loading data into a scratch org made simple
Although scratch orgs are meant to be individual workspaces for exploring and testing features in isolation, working collaboratively can help overcome various challenges.
Issues such as configuration management, data loading management, and managing multiple scratch orgs become more efficient and streamlined with collaboration.
Collaboration also enables:
- Code sharing
- Data loading
- Dependency management
- Workflow optimization.
These factors lead to increased productivity and efficiency.
🥇
With Hutte, teaming up with others simplifies scratch org data and enhances the development process.
Spring Release Updates
Capture a Scratch Org’s configuration with the new Scratch
Org Snapshots feature, which is currently in beta.
Scratch Orgs now come with more options for customization and configuration to better match your development needs.
There’s guidance available for troubleshooting login issues after Multi-Factor Authentication (MFA) was automatically enabled for your org.
Authors